1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
| <?php
namespace app\common\library;
use app\common\exception\BusiException;
use PhpOffice\PhpSpreadsheet\IOFactory;
use PhpOffice\PhpSpreadsheet\Spreadsheet;
class Export
{
private $cellIndex = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'AA', 'AB', 'AC', 'AD', 'AE', 'AF', 'AG', 'AH', 'AI', 'AJ', 'AK', 'AL', 'AM', 'AN', 'AO', 'AP', 'AQ', 'AR', 'AS', 'AT', 'AU', 'AV', 'AW', 'AX', 'AY', 'AZ'];
public $config = [
'bold' => true,
'size' => 12,
'column' => 4,
'title' => '默认导出',
'name' => '特抱抱',
'type' => 'Xls',
];
public $tableHeader = [
'php',
'vue',
'java',
'go',
];
public $tableDefaultData = [
[
'天下第一',
'Vue牛逼',
'java牛逼',
'go牛逼',
],
];
public function __construct($tableHeader, $tableDefaultData)
{
if (empty($tableHeader)) {
throw new BusiException('export error', '请设置表头');
}
if (empty($tableDefaultData)) {
throw new BusiException('export error', '请设置导出数据');
}
$this->tableHeader = $tableHeader;
$this->config['column'] = count($tableHeader);
$this->tableDefaultData = $tableDefaultData;
}
public function createTable()
{
$spreadsheet = new Spreadsheet();
$worksheet = $spreadsheet->getActiveSheet();
$styleArray = [
'alignment' => [
'horizontal' => \PhpOffice\PhpSpreadsheet\Style\Alignment::HORIZONTAL_CENTER,
],
];
$worksheet->setTitle($this->config['title']);
$worksheet->getStyle($this->getColumn())->applyFromArray($styleArray)
->getFont()
->setBold($this->config['bold'])
->setName('Verdana')
->setSize($this->config['size']);
foreach ($this->tableHeader as $index => $name) {
$worksheet->setCellValue($this->cellIndex[$index] . '1', $name);
}
$baseRow = 2;
foreach ($this->tableDefaultData as $index => $data) {
$i = $index + $baseRow;
for ($k = 0; $k <= $this->config['column'] - 1; $k++) {
$item = $data[$k];
$worksheet->setCellValue($this->cellIndex[$k] . $i, ' ' . $item);
if (preg_match("/[\x7f-\xff]/", $data[$k])) {
$worksheet->getColumnDimension($this->cellIndex[$k])->setWidth(strlen($item));
} else {
$worksheet->getColumnDimension($this->cellIndex[$k])->setAutoSize(true);
}
}
}
$worksheet->calculateColumnWidths();
self::downloadExcel($spreadsheet, $this->config['name'], 'Xls');
}
private function downloadExcel($spreadsheet, $filename, $format)
{
if ($format == 'Xlsx') {
header('Content-Type: application/vnd.openxmlformats-officedocument.spreadsheetml.sheet');
} elseif ($format == 'Xls') {
header('Content-Type: application/vnd.ms-excel');
}
header("Content-Disposition: attachment;filename="
. urlencode($filename) . '.' . strtolower($format));
header('Cache-Control: max-age=0');
$objWriter = IOFactory::createWriter($spreadsheet, $format);
$objWriter->save('php://output');
exit;
}
private function getColumn($row = 1)
{
$index = $this->cellIndex[$this->config['column']];
return 'A' . $row . ':' . $index . $row;
}
private function autoFitColumnWidthToContent($sheet, $fromCol, $toCol)
{
if (empty($toCol)) {
$toCol = $sheet->getColumnDimension($sheet->getHighestColumn())->getColumnIndex();
}
for ($i = $fromCol; $i <= $toCol; $i++) {
$sheet->getColumnDimension($i)->setAutoSize(true);
}
$sheet->calculateColumnWidths();
}
}
|
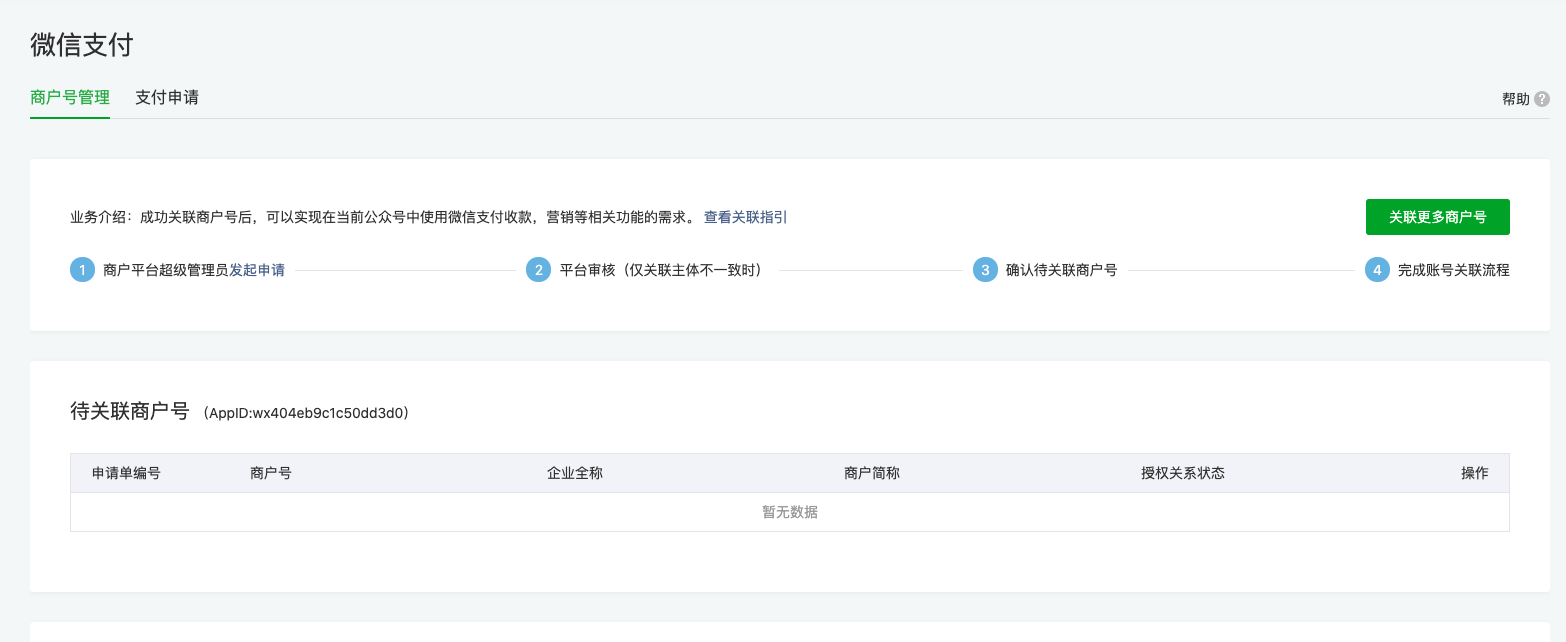 4.设置白名单、生成AppSecret(开发-基本配置)
4.设置白名单、生成AppSecret(开发-基本配置) 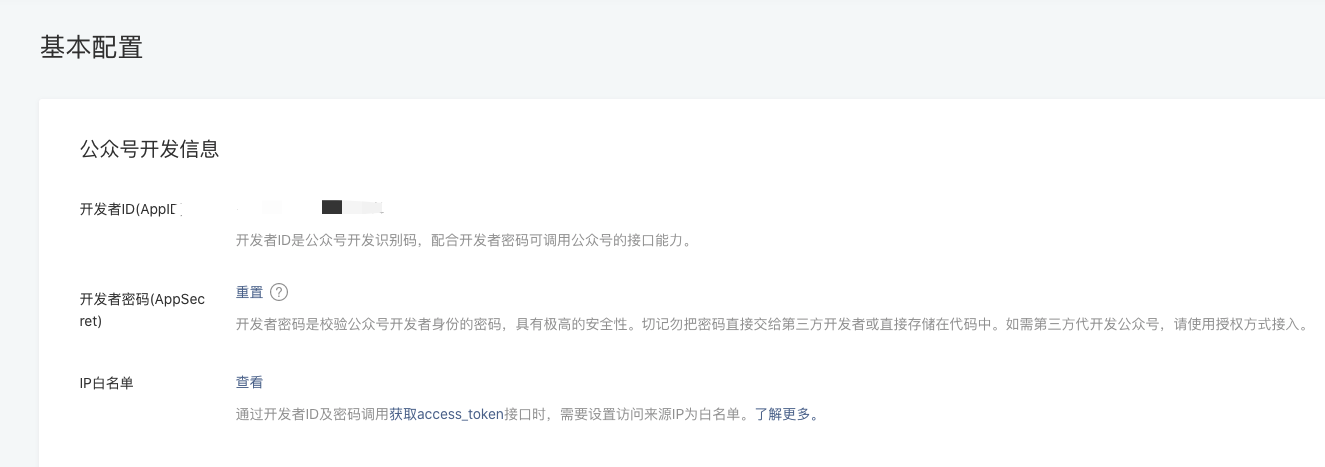 5.申请Api证书、设置APIv3密钥
5.申请Api证书、设置APIv3密钥 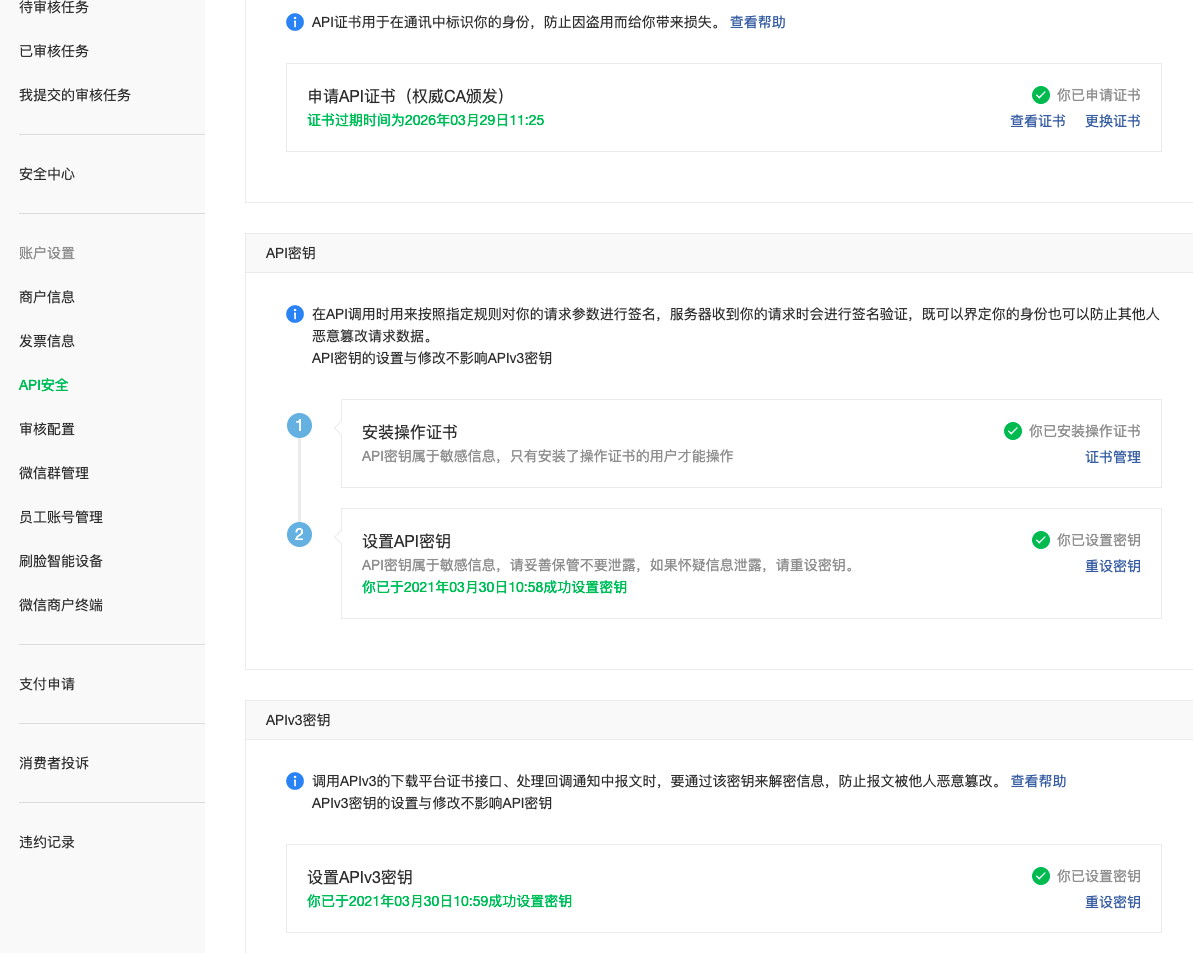 6.设置支付配置、jsapi支付授权目录、Native支付回调链接(产品中心-开发配置)
6.设置支付配置、jsapi支付授权目录、Native支付回调链接(产品中心-开发配置) 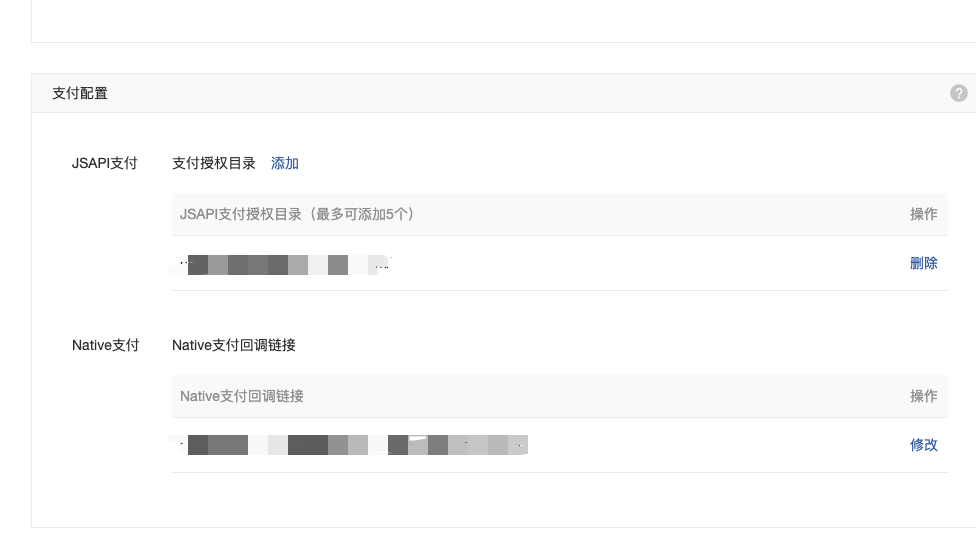



 ]]>
]]>
 ]]>
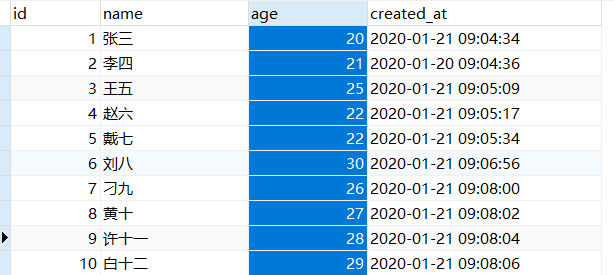
]]>
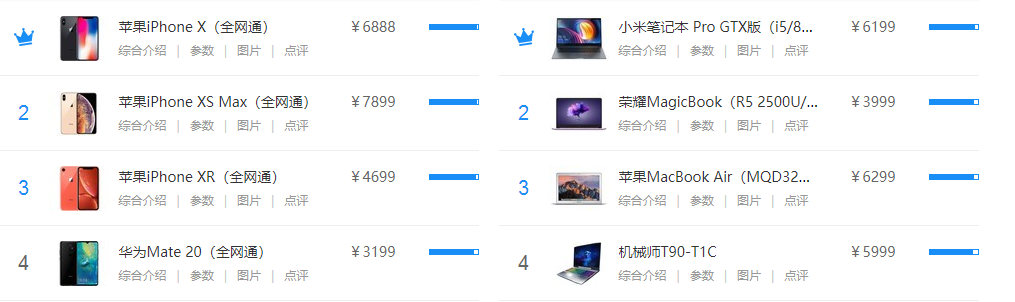





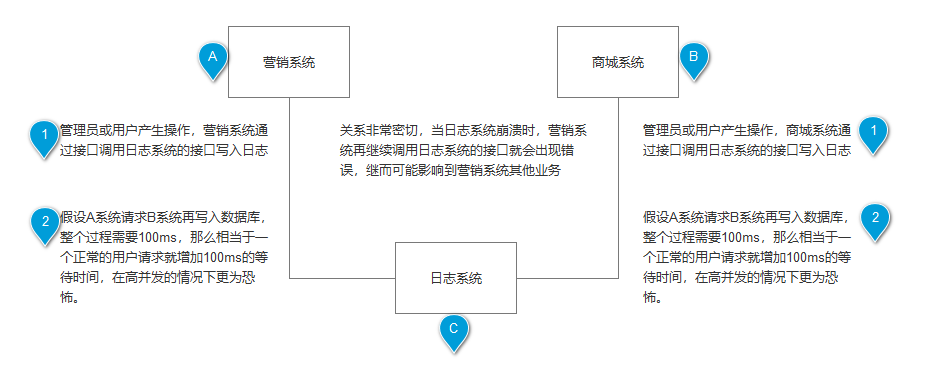 消息队列(MQ)写法
消息队列(MQ)写法